Section 02
数据采集层:五条管道全面接入
管道全景
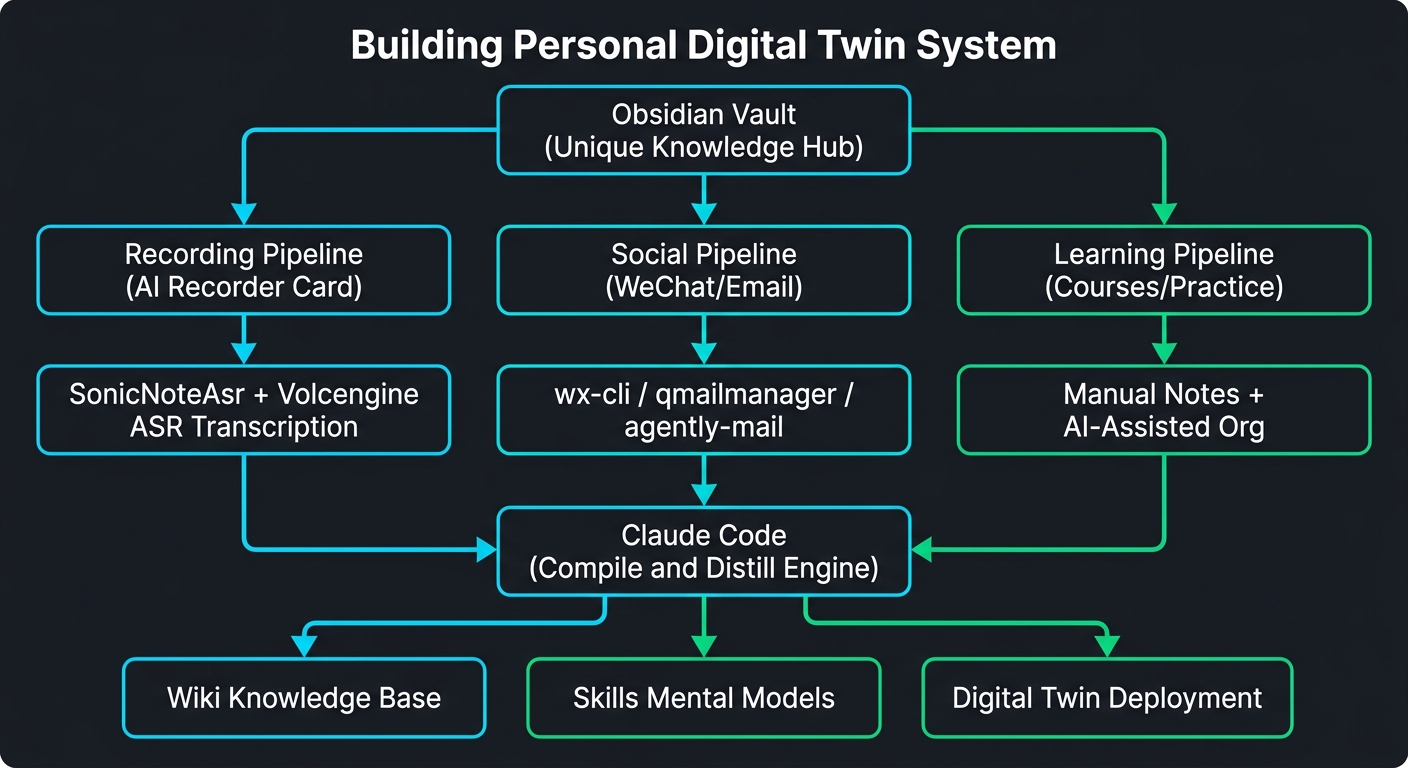
▲ 管道全景架构图 — 录音 · 社交 · 学习三大管道汇聚于 Claude Code 引擎(AI 生成)
管道一:AI 录音卡 — 声音→文字→知识
工具链:聆犀AI录音卡 → SonicNoteAsr Obsidian 插件 → 火山引擎 ASR → 录音笔记/
| 场景 | 采集内容 | 产出物 |
|---|---|---|
| 🏫 课堂 | 教授授课、课堂讨论、Q&A | 章节摘要 + 知识点卡片 + 待深入问题 |
| 🤝 会议 | 商业讨论、战略会议、项目复盘 | 决策记录 + 行动项 + 分歧点标注 |
| 🎤 演讲/活动 | 行业分享、圆桌讨论 | 关键观点提取 + 演讲者思维框架 |
| 💭 自言自语 | 个人思考、灵感碎片 | 想法卡片 → 后续发酵 |
工作流
① 录音 → AI录音卡自动采集,上传至云端
② 转写 → SonicNoteAsr 插件触发 ASR,生成逐字稿 + 说话人标注
③ LLM 总结 → Claude 按模板生成结构化笔记
④ 入库 → 自动写入 录音笔记/ 目录,Markdown 格式
# 录音笔记/2026-07-01-华科EMBA战略管理课程.md
date: 2026-07-01
source: 录音
course: 华科EMBA-战略管理
speakers: [张教授, 学员A, 学员B]
duration: 120min
tags: [战略管理, 课堂, EMBA]
status: 已总结
管道二:微信数据 — 社交关系→能力圈→人脉图谱
工具链:wx-cli / wechat-exporter → 微信笔记/ → Claude Code 分析
💬
聊天记录
思维方式、决策过程、社交网络的实时日志
🔄
朋友圈
兴趣圈层、信息消费习惯
👥
群聊
专业领域、协作模式
💡 关键原则:微信数据不进 Wiki,只从中提取「永久价值」——观点、决策、关系、承诺。原始聊天记录留在 Raw 层。
管道三:邮件数据 — 正式沟通→项目脉络→承诺追踪
工具链:qmailmanager726 / agently-mail / tencent-exmail
| 提取维度 | 说明 |
|---|---|
| 项目时间线 | 从邮件往来重建项目关键节点 |
| 承诺与交付 | 你答应了什么、什么时候交付、交付了没有 |
| 关键联系人 | 高频邮件联系人的角色、关系、历史 |
| 正式决策 | 合同、报价、确认函中的关键条款 |
管道四:学习资料 — 书本/论文/课程→知识卡片
工具链:手动笔记 + Claude Code 辅助整理 + Zotero 桥接
深化策略:Zotero 文献 → Claude Code Zotero 桥接 → 自动生成文献笔记;课程录像 → AI录音卡 → ASR 转写 → 知识卡片;实践项目 → 项目复盘 → 经验提炼 → 方法论沉淀。
